Content becomes intelligent, flexible, and capable of scalable personalization through structure and semantics.
Content drives customer experience (CX). In order to achieve optimal CX, we need the ability to manage multiple variations of content components that are dynamically assembled as relevant experiences, based on the context of the customer’s touchpoints. We need the ability to create a content component once, then reuse and deploy it many times, in many ways. This requires structured content with an intelligence shaped by semantics.
Structuring content within a well-defined content model makes content scalable, reusable, adapPage, and measurable. We cannot create real-time, personalized conversations at scale without structured, intelligent, semantically rich and truly accessible content.
In this article, we explore the role of content structure and semantics, governed by a content model, to reduce friction for both the content’s authors and consumers. We will also examine key distinctions between structure and semantics.
Structure shapes content with an object-oriented approach:
-
Content is organized as reusable content objects, rather than hard-coded, unstructured blobs.
-
Objects have containers, which can be manipulated, transformed, annotated, reused, and managed from a central location; they can be pointed to from anywhere.
Content semantics is the contextualization of content structures:
-
Content semantics define the entities, associations, and relationships for a given piece of content within the metadata.
-
Semantics is how machines can understand content connections and relationships.
We will also explore content and semantic models:
-
The Content Model is an orchestration layer for structural schemas.
-
The Semantic Model is an orchestration layer for taxonomies and vocabularies.
Why Content Must Become Intelligent
Content is what we acquire, manage, and leverage in order to engage and inform people. In order to effectively engage consumers, our content must be capable of movement and flow. Intelligent content is content that has been structured and contextualized so that it can:
-
Flow effectively and efficiently between people, machines, and applications.
-
Deliver individually optimized customer experiences at scale.
-
Maximize the return-on-investment made in its acquisition and management.
Content intelligence is a moving target, as the content itself constantly evolves, driven by consumer demands and needs. The channels for delivery are seemingly endless. We are also challenged with creating intelligent content that is ready to serve the demands of existing and future interactive channels.
Although most of us are focused on technical content creation, we must acknowledge the need to seamlessly integrate our content with other divisions of the enterprise. Working towards leaner, smarter processes that take advantage of automation and customer experience (CX) platforms helps eliminate costly barriers to customer engagement.
Pre-sales, marketing, and post-sales content must all work together to optimize customer experiences and ensure both customer retention and revenue growth. We accomplish this by structuring and contextualizing our content so that it can flow freely throughout the enterprise.
At the heart of this process of making content intelligent, the Core Content Model™ (CCM) ties everything together: it defines the relationships between content types and elements across systems, variants, and channels. We explore models further on in this article.
The Need for Structure and Semantics
In order to create intelligent content, we combine structured content with semantics. This powerful combination adds consistent, predicPage order to content, which in turn enables machines to work with it. The addition of semantics also optimizes the human value of the content by adding relevant context.
Once the content has become structured and enriched with metadata, transformation, reuse, and adaption to many different presentations for customer interaction become achievable. This is the key to automated, real-time personalization.
Core Content Model™ (CCM) to the Rescue
The Core Content Model™ is used to facilitate the complete, end-to-end content lifecycle and to enable optimization of content for each stage to plan, author, manage, and publish. It is a single integrated model that defines how content assets will be structured throughout their lifecycle. The CCM focuses on content structure and it accommodates semantics in the form of contextualized metadata.
The many different applications of the CCM must address all of the ways that content will be displayed and used by customers during the content’s lifecycle. To maintain flexibility, the CCM must be software- and vendor-agnostic. In short, the CCM connects the many ways that content is created to the many ways that consumers use it.
A Foundation for Scalable Personalization
The application of a Core Content Model™ significantly reduces friction typically experienced in content creation, management, and publishing. The CCM’s representation of publishing variations for structural elements makes dynamically connected and reusable content possible.
Structuring content within a well-defined content model makes content scalable, reusable, adapPage, and measurable.
Content modeling injects static content with enough technical intelligence to make it both dynamic and interactive. The CCM simplifies the development of content tools, apps, and APIs. If paired with the context provided by a CX database, content can be largely automated and used to generate real-time personalization.
Content Structure Through DITA
The most common solution for structuring technical documentation is the Darwin Information Typing Architecture (DITA), an open standard governed by OASIS. It was developed to solve problems of content reuse, interoperability, and omnichannel publishing.
DITA also helps provide the content’s baseline XML representation for the Core Content Model™; as such, it substantially reduces the number of transformations that are needed. Because DITA is component-based, it can be managed effectively with a Component Content Management System (CCMS). Unlike traditional Content Management Systems (CMS) that primarily work at the document level, a CCMS can facilitate content reuse at the component level. This significantly increases the content’s ability to flow across systems and solutions.
Enterprises, especially departments who create technical documentation, should care about DITA because it supports:
-
Open standards
-
Topic-based orientation
-
Core structures
-
Efficient and reuse mechanisms
-
Specialization
The basic DITA structures that are the most relevant to technical publications are topics and maps. The illustration below shows content types and content elements typically found in traditional, DITA-based technical documentation.
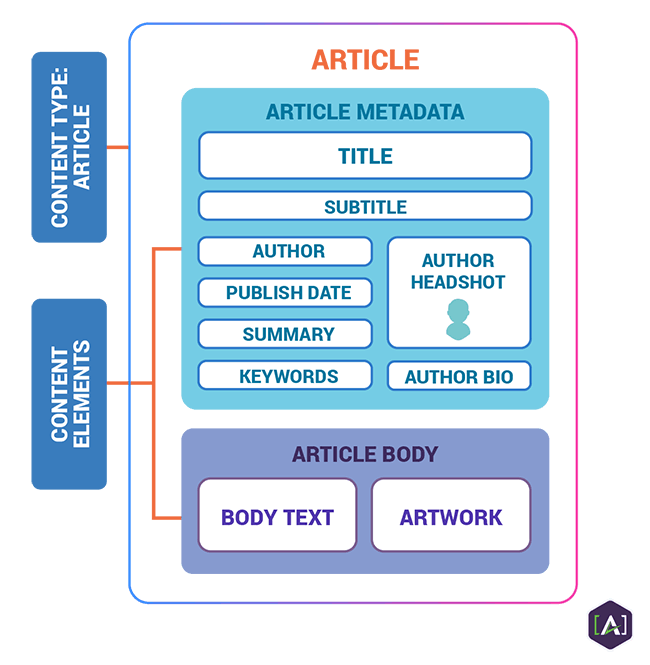
Content Structure, Semantics, and Metadata
Content structure: Structure is the organization of things. Content structure is the physical organization of content; it addresses the fundamental needs of publishing — presenting content to people.
Content semantics: Semantics is the study of meaning; meaning emerges from information within systems. Content semantics is the association of specific meanings with specific content structures. Meanings are established as a context within a semantic model.
Semantic Models define and organize concepts within knowledge domains. At [A], we have found the following three types of models for semantics to be the most useful:
-
Taxonomy: A classification scheme
-
Thesaurus: A rubric defining and relating terms
-
Ontology: A formal, machine-interprePage domain model
With the added intelligence we have described thus far, we can apply more rules and more properties to content objects to enable some type of useful machine interpretation.
There is an entire ecosystem in the content technology landscape around semantic services. You may wish to read, “Surveying the Semantic Services Vendor Landscape”.
A Core Semantic Model is essentially a comprehensive model that defines concepts and their relationships. It also defines the terminology for identifying concepts across a domain and across systems; this informs the Core Metadata Model that is incorporated into the Core Content Model®. The relationship between our three main models is illustrated below.
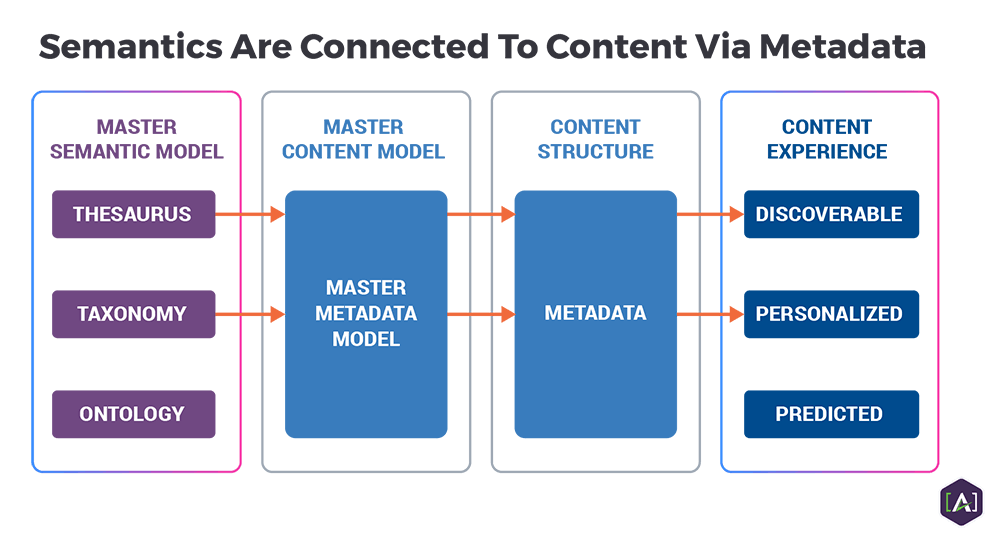
At [A], we have found that Core Semantic Model development works best as a four-step process:
- Inventory: Collect any existing semantic models and supporting information.
- Analyze: Identify semantic requirements and evaluate existing models.
- Design: To define semantic models, as well as relationships and context.
- Demonstrate: A test demo or pilot to illustrate how the semantics apply to existing content assets.
Establishing and testing metadata is an iterative process. We eventually establish a Core Metadata Model (CMM) that helps define the structure and potential context for content, working within the Core Content Model®.
The Role of Metadata
Metadata is the critical intersection of structure and semantics. We use it to reflect the semantics we need in our structure so we can support both our content applications and our semantic applications.
Semantics are connected to content via metadata. The graphic below illustrates this connective role of metadata, which can produce different presentations or behavior for the same content asset.
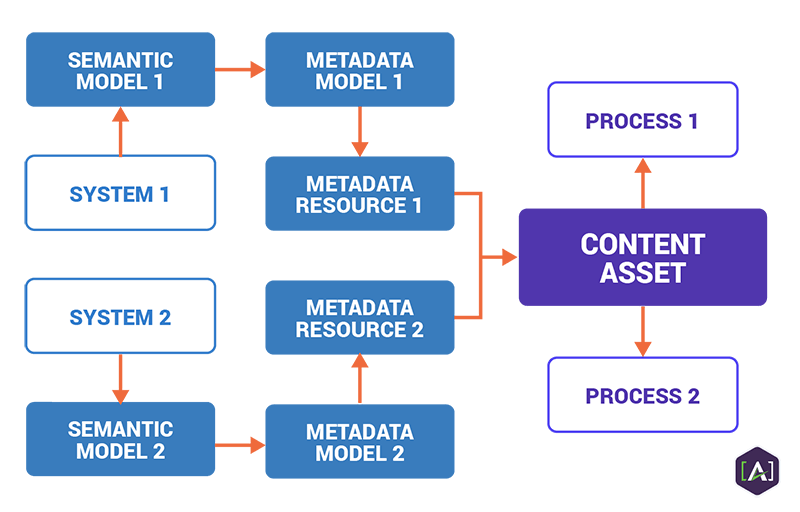
At its most basic level, metadata tells us what is potentially going to happen to a thing or a piece of content. Meta means “after” in Greek. It indicates what can happen to content “after” an applied action or a certain usage.
Metadata resources are:
-
Related to external systems which ultimately control the source data.
-
Intended to be useful to downstream processes.
-
Reusable across content sets, across systems, and across downstream processes.
Think of the Core Metadata Model (CMM) as encompassing the connectors between structure and semantics. Connectors could include:
-
CMS Metadata
-
Markup
-
Knowledge Graphs
-
JSON-LD
-
RDF
Conclusion
Structured content, enhanced with semantics and metadata, empowers our content assets to decrease effective costs and deliver relevant content interactions to the right audience at the right time. The velocity of content throughput and distribution increases return-on-investment for pre-sales and/or post-sales content.
We, at [A], have discovered that content structure is the physical organization of content. It is the form that content takes when represented in a base, like XML, or within other representations of a content object’s schema. When structure agrees between systems, or maps, cleanly from element-to-element, content can move between those systems. Content semantics are used to provide essential context for content structures, making it possible to provide advanced content experiences, such as automated personalization. And, finally, metadata is the way we associate specific content structures with specific semantic contexts as defined within one or more semantic models. We make these associations by “annotating” content with metadata.
Content structured for motion creates more value than static content ‘at rest’. Content in a traditional, static forms (e.g. PDF or chunky unstructured HTML) still serves an important purpose, but it has limited findability, narrow utility, and it cannot dynamically serve context-driven interactions. Engineering content for portability makes intelligent customer experiences possible. Over time, static content will get less and less relevant for customers.
Content only has true value for customer engagement when it is in motion. In order to be in motion, content must become intelligent. To become intelligent, content must become structured and enhanced with semantics.
Dynamic, personalized customer interactions are only possible with intelligent content that can flow through and across systems and processes.
References and Further Reading
Despres M. (2014) ‘Advancing technical communication’ Communicator, Autumn 2014: 38-41
Hoffmann M. (2019) ‘Collaboration: the future of content’. Communicator, Summer 2019: 40-42
Hoffmann M. (2019) ‘Surveying the Semantic Services Vendor Landscape’. [A]. https://simplea.com/Articles/semantic-services-vendor-landscape (accessed 18 July 2019)
McDonald A. and Ressaire T. (2017) ‘Contextualisation and molecular content’. Communicator, Summer 2017: 40-44
Saunders C (2018) ‘Introducing the Core Content Model™’. Medium.com. 13 December 2018. https://medium.com/@cruce/introducing-the-master-content-model-621449471426 (accessed 18 July 2019)
Glossary
Content semantics: The association of content structures with specific semantic contexts given one or more semantic models that define and organize the concepts within relevant knowledge domains. Content semantics are used to provide essential context for content structures, making it possible to provide advanced content experiences.
Content structure: The physical organization of content; it addresses aspects such as how content will be modularized, identified, addressed, and reused.
Core Content Model™ (CCM): A single, integrated model that defines how content will be structured throughout the complete content lifecycle.
Master Metadata Model (MMM): Helps define the structure and potential context for content, working with the Core Content Model™.
Core Semantic Model (CSM): A comprehensive model that defines concepts and their relationships.
Metadata: On a general level, it is essentially a set of “statements”; each statement consists of a property or element and its associated value. Within the context of this article, metadata is the way we associate specific content structures with specific semantic contexts as defined within one or more semantic models.
Ontology: A formal description of knowledge as a set of concepts within a domain, and the relationships that are held between them. By having the essential relationships between concepts built into them, ontologies enable automated reasoning about data.
Semantic models: Define and organize concepts within knowledge domains. At [A], there are three types of models: taxonomy, thesaurus, and ontology.
Semantics: Represents the formalization, documentation, and publishing for use of the concepts, with their interrelationships, that are meaningful within the business of an organization.
Taxonomy: A classification scheme that helps you to organize your content and assets into hierarchical relationships. Content assets classified in a taxonomy are better optimized for internal and external searches.


