Teams hoping to scale personalization technology are realizing the importance that the shape of content takes in designs, content systems, and APIs. Content structures have taken a leading role as the ingredients necessary to dynamically build relevant experiences for customers. Investments in headless content and commerce platforms reached more than $1.6 Billion this year (Forbes), demonstrating that the drive toward structured and modular content continues to increasingly attract attention. This attention is well placed because all personalization ultimately depends on content assemblies – meaning application of content componentization so machines can then surface relevant components based on logic. And content assemblies ultimately rely on structure.
As customers, we seek the most relevant information because it’s the most efficient use of our limited attention. With every interaction, we need to figure out what’s relevant to us. Regardless of how we arrive at an information landscape, we arrive looking for relevance. We don't have the capacity to process everything, so we sort for relevance very quickly. We ask "what is the most meaningful content right now" and mentally discard everything else. Research shows that customers bounce off websites within 5-10 seconds of arrival, down from 15-20 seconds a decade ago (nngroup). Imagine the mere milliseconds we allocate for relevance-sorting when scrolling through social media or scanning through unopened emails.
As content relevance matters more and more, so too does personalization. Relevant content helps everyone conserve valuable mental space, as well as time and money. This article focuses on content relevance and structure, examining:
- The challenge of recognizing and managing content structure
- The role of content assembly in real-time marketing
- How content models facilitate content portability and targeting
- Examples of invisible or unrecognized content structures
- Mapping customer experiences to content structures
The Varieties of Content Relevance
The “moment of relevance”, sometimes called a “moment that matters”, arrives when a component containing content becomes most useful to a customer.
Let’s look at three types of content relevance:
Intent-driven content relevance: Content most often gains relevance when it successfully matches a customer’s intent or goal. Intent can be specific (“find a solution to a specific error”), broad (“find something fun to do outdoors in the winter”), and everything in between. The important part is that the customer carries the intent, so the content should match that intent as much as possible. Matching a response to an intent defines the essence of this kind of relevance.
Timeline-driven content relevance: Specific content becomes useful to a customer or user at specific points in time within their journey while engaging with a digital experience or brand. Here, we leverage the notion of injecting content structures into a timeline. Customer use cases for this approach include:
- The need to learn something at a given moment
- Employ content to perform a task
- Use content to solve a problem or spark a realization
- Advance from one step in their journey to the next journey with an organization.
Within these specific moments in time, the customer requires specific content to help them meet their needs.
Profile-driven content relevance: Specific content proves useful because the customer is part of a demographic identified by an analytics team, including but not limited to age, gender, location, and interests. In these scenarios, content relevance includes matching content with customer data on specific attributes and segment paradigms.
In general, consumers lack the time to read through all the information presented to them. Many organizations and brands present consumers with too much information, and users will not sift through lots of long-form information when they really need a fraction of that input. Notwithstanding, most consumers prefer to spend time with the most pleasurable and frictionless content experiences.
In all of these cases, the assembly of structured content components for the right person, at the right place, on a timeline, is the hallmark of a personalized, relevant, positive customer experience. Getting some unit of content in front of someone based on intent, timeline, or cohort is the goal and the primary challenge for teams attempting to achieve relevance.
Modular Content defines the Baseline for Intelligent Experiences
Relevant intent-response matching forms the foundation of Intelligent Customer Experiences (ICX), an approach to content and customer experience [A] has pioneered with enterprise publishing teams. In ICX, a technology platform determines customer intent and then responds with appropriate content that seeks to meet the customer’s needs.

Many organizations have mountains of under-utilized data facets about customers available. Profiles get stored in environments such as Customer Data Platforms (CDPs), or large data warehouses, often carrying hundreds of attributes. Connecting all the data facets to all the content components that a company produces takes some effort. And where does one begin with tagging these data points and associating them with content? Semantic models are the solution. [A] covers semantics in depth across articles and webinars, most notably in the paper Introducing the Core Semantic Model.
Real-Time Marketing and the Invisible World of Content
Organizations often start with relevance for marketing messages, and for good reason: 84% of customers report they are more likely to buy from companies that personalize content (Salesforce). It's not surprising that 90% of digital businesses say they leverage at least one personalization program (Forrester) and look to grow investments in personalization.
Real-time marketing involves content modules matched to customers and customer behaviors. Any honest conversation about real-time marketing must acknowledge that content needs to exist in a manageable structure that allows for targeting. How do we deliver the right information to our suppliers, partners, and customers based on what they need, when they need it? And do so based upon their context? We answer the question simply with: “Structure!” Real-time or dynamic rendering of content cannot happen without content structure.
You may not be aware of how structure informs content, but structure exists everywhere in content experiences, either accidentally or with intention and purpose and engineering.
The assembly of relevant content depends entirely on having logical content structures available for machine discovery and presentation. These content structures already express themselves in many places across your content and customer experience ecosystems. [A] works with clients to identify, standardize, use, and manage content structures, or “content models”. Any team working on personalization should have a dedicated function for managing the content structures that underpin all modular customer experience.
Content structure itself involves the identification and categorization of content elements with an experience --Titles, Tag Lines, Images, Content Snippets, Offers, Questions and Answers, Descriptions, etc. -- as part of a content engineering approach to determine the parameters and behavior of modular content. Regardless of the technology involved, systems need to manage content structures in order for personalization to happen in a meaningful way. And as a best practice, content should remain fluid, flexible, and decoupled from presentation.
An effective approach starts with the content engineer or content architect identifying the content structures as content types and their relationships. This usually starts with a Content Relationship Diagram, or content domain model. With the content types identified, teams then build out the content elements and attributes for each content type. The content types, elements, and attributes form the basis for the content model. Once a content model is defined, technology teams can configure systems to understand and utilize the structured content. Then assembly can occur, where components can surface in any digital channel based on the rendering rules, leading to a response to customer context to deliver personalized experiences.
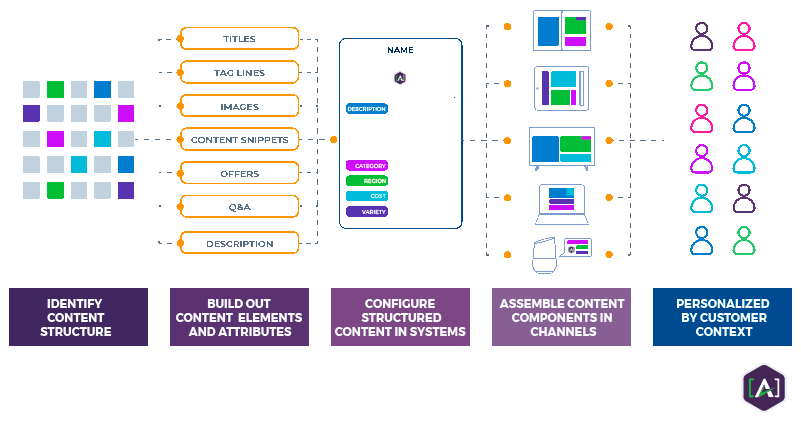
In some organizations, content structures remain overlooked entirely. Some teams view structures merely as a presentation template, or they deem content structure as a secondary effect of UX design. Sometimes teams consider structure only when creating the functional specifications for a Content Management System (CMS), or when designing the stylesheets for a page layout. However, these examples are more focused on the designed rendering of static content.
We are Surrounded by “Invisible” Structure
Before we examine methods of content management, let us revisit some of the places that content structure lives. Content structure remains so pervasive that we often do not recognize it, even as it is embedded in tools or procedures that we use every day.
The following table presents examples of where structured content lives within a content ecosystem or instances that require structured content to enable a transaction.
| LOCATION | DESCRIPTION |
| DTP platforms / authoring | Inherent structure exists even within an MS Word document: headings, subheadings, lists and such. Much technical documentation has migrated over to XML format, where document structure contains more intent and where metadata enables post-processing to occur for presentation and other actions. |
| Presentation Templates | Content structures often get baked into design systems. Component-based content can work efficiently with component-based design patterns when the content models are teased out of the templates and built into a separate system. |
| Records Management (CMS, CCMS, DAM, etc.) | An organization’s source content pool has a great deal of structure already. Tagging and metadata in a knowledge base offers a great source for metadata. Any applications that store content express content structure. |
| Document markup and markdown standards | Markup, or even lightweight markdown, standards for documents that are heavily reliant on inherent structure can delineate both format-based and logical content structures. |
| Source Code Repos (GIT, CVS) | Structural tags and containers are used to delineate, locate, and retrieve source code. Metadata fields and sometimes code comments are rich with useful content structures that need to be added to your overall Core Content Model. |
| Voice | Voice UI and navigation is becoming more common. Often these systems rely on highly structured content sources. In healthcare, there are “symptom checkers” and algorithm-based triages that can function as sources of inherent structure. |
| SEO | Technical SEO relies heavily on content structures (“structured data”), and gets mapped via your Core Content Model to essential standards like schema.org. |
Identifying and incorporating content structure across various representations into a functional, unified content model finally makes it possible for an organization to facilitate movement of its content objects across its entire content ecosystem. This movement includes a whole series of content-carrying applications and a whole bevy of downstream consumption channels via headless content APIs.
Models and Content Portability
When structured content is machine-readable, systems can retrieve and locate relevant content automatically. A key function of content models is the orchestration layer, which renders content consistently as both human and machine consumable. This guideline persists wherever the content goes, and however it gets targeted out for assembly via a content recommendation algorithm or machine-learning optimized method.
Beyond the benefits of improved organic search, content structure enables the connection between content source and delivery methods via APIs. One benefit of building and managing content structural standards is that it keeps content fluid and in motion throughout the content supply-chain, so that the many systems of engagement can reliably pull the content components needed for intelligent experiences.
Companies that approach [A] often have many advanced content targeted systems in place, but they lack a unified approach of getting content to work consistently across even a single platform layer with multiple instances, let alone across many platforms across the global enterprise. Building a unified model is a breath of fresh air, because it rationalizes and organizes a chaotic landscape.
From authoring standards (e.g. Schema.org) to industry-specific standards (e.g. medical or construction), content structure plays a major role in portability and content around the world. Content cannot move without structure. Structure comes from content models. But we do not need to constrain content to one model artificially. The future requires flexible models that can adapt and transform. Then we can build nimble content supply chains with the power of nodal transformation. This will allow us to build new outputs and channels for content using these same elements and attributes of content. Content flexibility starts with flexible content models.
The Core Content Model
For practicality and effectiveness, the conscious design of an internal standardized ![]() content model to support an omnichannel and omni-source world remains pivotal for all personalization. This standardized content model that crosses many content types and platforms is what we at [A] refer to as The Core Content Model (CCM)™. This concept represents a single, integrated model that defines how content assets will be structured and represented throughout their complete content lifecycle. Key takeaways about the CCM include the following:
content model to support an omnichannel and omni-source world remains pivotal for all personalization. This standardized content model that crosses many content types and platforms is what we at [A] refer to as The Core Content Model (CCM)™. This concept represents a single, integrated model that defines how content assets will be structured and represented throughout their complete content lifecycle. Key takeaways about the CCM include the following:
- The CCM™ focuses on the structure of content — its literal physical organization into components that can be enriched, reused, processed, and consumed.
- By defining the structure of content assets, the CCM facilitates the creation, exchange, and utilization of valuable modular content assets.
- To achieve effective results, a content model must incorporate semantics by reference. Here, semantics refers to the introduction of enriched meaning (“tags”) into the content in such a way that applications can find, interpret, and act on content. Relevance depends on semantic matching content with customer data related to the same topic or intent tags.
- The CCM™ seeks to encompass the complete content asset lifecycle, from planning to delivery and use. This lifecycle orientation is important, as it is a central goal of The CCM™ to facilitate the representation of content structures in every application that will need to access, display, manage, and potentially modify the content. In this way, the CCM™ enables the flow of content across all of the applications that play a role in the content lifecycle.
Matching content structures with the customer’s contextual data
After we have content structured into a model that we actively manage, we are halfway to personalization. We must also match content structures with customer data, then apply this logic through the right channels at the right time. How does this magic happen? Science, of course. Enter the world of semantics, which includes controlled vocabularies, aligned taxonomies, metadata and tag management systems, terminology management systems, tight content governance, and, in some cases, ontologies and knowledge graphs. This is the information about what our content actually is and how it gets tagged, along with what the customer needs. All of this data about data and nomenclature rules remains largely invisible to the end user, but provides the context for machines on how to treat, serve, and assemble the content to best meet the customer's needs. Enterprise-level content systems often need to manage semantics separately in a Core Semantic Model being run in a semantics software, the source of truth. As a point of reference, you will find several resources on simplea.com which discuss the functions of the semantics model.
Persistence with Personalization
Personalization should not be an afterthought. Successful personalization exists as an emergent effect from many causes, some of which are ongoing and others that are intentionally implemented. Most personalization efforts will fail if treated like a one-time project, campaign, or a feature within a piece of software.

So far we have surfaced several points; to summarize the key takeaways:
- Intelligent Customer Experiences rely on modular content
- Modular content relies on consistent structure
- Consistent structure depends on The Core Content Model™ (CCM)
- A core content model depends on engineering and orchestration
Mapping Customer Experiences to Content Structures
In order to start developing intelligent customer experiences, the path to personalization starts, as many things do, with a definition of the outcomes. To define these outcomes:
- Identify the “moments of relevance” where content recommendations and assemblies will drive measurable (and customer-memorable) value
- Break those moments into their components of UX, structured content, and semantic elements
- Align the components with larger enterprise content standards
- Build a plan for implementation using the components identified
- Build integrated team alignment and teamwork necessary to produce and bring all the elements together
Department teams, product teams, omnichannel content, and CX teams can all own this kind of work, often in partnership with their internal and external technology partners. [A] facilitates building structured content models with clients. And teams never cease to be surprised at how much progress can be made quickly with a coherent framework.

No matter how advanced the underpinning technology, Intelligent Customer Experiences fundamentally require teamwork and collaboration. Organizations should not view personalization as a project: it is a practice. It requires new ways of working that support modular content creation, management, and targeting. All of this starts by rallying a team around a defined and managed content model.



