A graph database is a way of storing, accessing, and navigating large interrelated datasets that makes relationships between data as essential as the data itself. It also follows that graph databases create new forms of relationships between content strings, that become very useful for personalization and other dynamic effects across content sets. Another way to see a graph database is as a ‘brain’ that connects up a whole matrix of ideas into a coherent whole. This ‘brain’ gives machines a way to understand concept relationships in a faster, more powerful, and complete way than a relational database.
Like NoSQL databases, graph databases have gained popularity as a data management solutions evolve to meet the demand organizations face as we encounter more large and diverse data and content streams.
The graph database works as a tool for connecting data objects at scale, with a great, heterogeneous continuum of sources. Compared to the legacy technology used in enterprises for years, the emerging technology of the graph database is a better optimized, more efficient, and more cost-effective way to handle the new kinds of data underlying complex and highly-connected information structures. Graph technology solutions underpin recommendation engines and advanced search, and provides us with intelligent ways of solving the challenges today’s digital networked knowledge presents.
The tech companies are leading the way, but the enterprise is rapidly adopting graph databases.
Among the most popular companies leveraging graph technology in the recent years are Google, Amazon, AirBNB, Uber, Netflix, eBay, LinkedIn, and Facebook. These tech giants all use graph databases to power solutions for recommending, retrieving, matching, and serving content to users, devices, and other data. This is largely due to the potential graphs have for scalability, expressivity, and cost-effectiveness as a data management solution for these complex data ecosystems.But it’s not just the new-era tech companies - enterprise and publishing leaders are catching on, fast. Innovators such as Siemens, Cisco, NASA, KPMG, and the BBC have all begun investing in graph databases.
The graph database market is gaining momentum. This is not to say that it will entirely replace other database models — it is not the right fit for every data system — but the graph database is enhancing, and in many ways revolutionizing, management and storage solutions for those certain use cases and application strategies that require connections, smarts, and speed across large, changing content and data sets.
Designing for a Revolution: The Science Behind the Graph
"[There is] a third revolution in database technology. The first revolution was driven by the emergence of the electronic computer, and the second revolution by the emergence of the relational database. The third revolution has resulted in an explosion of non-relational database alternatives driven by the demands of modern applications that require global scope and continuous availability."
—Guy Harrison, Next Generation Databases: NoSQLand Big DataGraph databases and the technologies related to their development add another layer of richness to the way we are able to represent real-world objects on a conceptual level. This is largely possible thanks to the graph — a mathematical construct used for modelling and solving a large array of problems related to networks in the field of physics, biology, sociology, and information technology.
Computer science uses graphs and graph theory to model relationships between data objects and represent various networked structures. Graphs are used to map relationships between linked objects, related people, clusters of chemicals, value-chains, and much more.
The graph structure consists of nodes connected by edges.
The graph database world is filled with layered solutions, various degrees of graph technologies, and diverse implementations. While some graph technologies are built as standalone solutions, others deploy graphs on top of existing technologies. Regardless of the different approaches, graph processing boils down to mapping, managing, and analyzing granular, many-to-many relationships and their types.
Choosing the Right Data Management Solution
When Is a Graph Database the Right Fit?
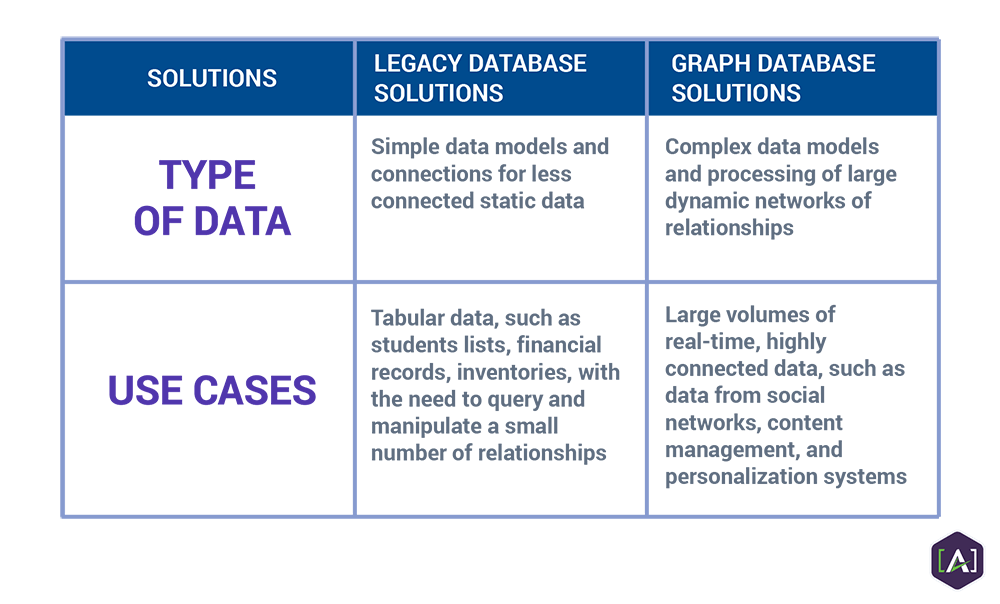
Graph databases are hardly a "one size fits all" solution. The type of data, use cases, and available resources should all be considered when deciding to move forward with the graph model or a more traditional data management solution, like the relational database.
Graph databases are suited to handle volume, variety, and velocity.
Managing data as graphs is a particularly good fit when the use case involves modifying schemas and accommodating new features, data points, or sources.Graph databases are ideal for instances where elements will need to simultaneously relate to each other, be easily accessible, and query millions of relationships per second. Such data and data management systems are needed to integrate information for chatbots, conversational systems, social applications, recommendation algorithms, optimization applications, routing, and maps — all real-world interactions that need to be stored as densely connected structures and navigated seamlessly.
AI and machine learning applications tremendously increase in value when configured to work against graph databases, because they can now understand and analyze the edges, or relationships, between entities within the dataset or the content set in the graph form. At [A], we see graphs as essential long-term for true AI, and essential to true personalization.
Graph databases also run more efficiently across highly-connected datasets. Other data management solutions usually cost more to run. For example, in the case of social media streams, where data and query connections may be in the many thousands per millisecond, or in the case of new customer interactions, where data is constantly changing, graph technology can meet the need to accommodate such ever-growing, ever-changing, and diverse data and content sets. It is the graph database that serves as a container capable of handling such quantity, diversity, and speed of customer interactions with our content, and the data all that activity generates.
Graph databases are also most often the right fit for database management challenges related to harnessing the heterogeneous content and data from diverse sources (XML, CSV, relational data stores, and other formats), constantly-changing data (IoT data, real-time interaction data), data siloed across different systems (marketing, sales, support, training department), and data where the value of which grows when interconnected (social graphs, interests graphs, user-generated knowledge graphs, context graphs).
When Is a Graph Database Not the Right Fit?
In the right context, graph databases are an incredibly powerful tool. But enterprises must take into account the overall vision and how to model and solve for their own unique organizational challenges to determine the best path forward. There are plenty of cases where another data management technology is the best solution.Not all enterprise data needs to be forced into a graph. Additionally, not every enterprise is ready to build a graph database given the significant investment in both time and resources.
A relational database, for example, is better suited for handling transactional data, such as accounting records. A graph database is often far from being an out-of-the box solution. Organizations may find that they prove too costly to build and maintain if huge numbers of records need to be queried and their relationships are not as important. In this situation, relational databases are much better suited for this task. This is also the case when the demand to query and manipulate relationships is minimal, like managing data that describes information about students lists, financial records, or inventories, for example.As much as graph databases are very useful and efficient when it comes to managing dynamic data, they prove to be an inefficient solution when it comes to managing static data. A different approach is needed.
The Nodes and Edges of Intelligent Content
The flexibility and agility with which graph databases deal with complex informational structures allows content engineers to build a more powerful ecosystem of intelligent content.There is a great potential for graph databases to make content smarter and more connected than ever. Content engineers can use graph databases as a tool to orchestrate content blocks, create consistency of stories and knowledge, and establish standardized meaning for interconnected structures. This creates an ecosystem that is ready for intelligent content outputs such as:
- Designing personalized experiences
- Providing ease of access to content resources
- Enabling seamless search and discovery interactions with the system
- Efficient access to internal and external resources
- Topic clustering
- Contextualized content serving
- Conversational interactions
- Storing and analyzing customer context data
- Working with content sets within a highly-interconnected system
In a world of wildly emerging touch points of user interactions with content and data, graph databases can provide a platform for content engineers to design for richer experiences, broader reach, deeper engagement, and ultimately the greater use that highly-connected data brings to the world of content.



