The Semantic Web is the knowledge graph formed by combining connected, Linked Data with intelligent content to facilitate machine understanding and processing of content, metadata, and other information objects at scale.
While the concept of the Semantic Web, sometimes known as Web 3.0 or Web of Data, is still unknown to many, it has been around since the early days of the Internet. Tim Berners-Lee considered The inventor of the World Wide Web and creator of the Semantic Web concept coined the term in 1999 in “Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor.”:
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.”
 In the 2001 Scientific American article “The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities” by Tim Berners-Lee, Hendler, and Lassila, Berners-Lee further described his vision of a Semantic Web and the expected evolution of the existing Web to a Semantic Web.
In the 2001 Scientific American article “The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities” by Tim Berners-Lee, Hendler, and Lassila, Berners-Lee further described his vision of a Semantic Web and the expected evolution of the existing Web to a Semantic Web.
In Berners-Lee’s vision, the Semantic Web is about using metadata to assign meaning to all the data on the Internet to make it machine-readable and create a knowledge graph that categorizes data into entities and describes the relationships between those entities.
This article will explore what the Semantic Web is, its purpose and benefits and expected future evolution.
What is the Semantic Web?
Computers are fairly dumb machines. They follow sets of instructions and provide an expected outcome based on rules. They don’t have a mind of their own or an understanding of the meaning of content or data.
As such, in its early days the Internet-connected servers displayed information in a fairly unintelligent way, not understanding the search intent or context, nor establishing a relationship between data and content. And the same was going on with all computer systems, private, public, local, or on the World Wide Web. Semantics - which provide meaning - were not part of the data and content.
If you need a definition, this is probably the best definition to describe the meaning of the Semantic Web:
The Semantic Web envisions an intelligent internet where the published content and data are adjoined with an additional set of machine-interprePage data - metadata and Linked Open Data - to provide semantics - meaning - as well as establish context - relationships between the data and content. These two types of data (semantic metadata and Linked Open Data) form the basis of the Semantic Web.
The ultimate purpose of The Semantic Web, of enriching data and content with semantic metadata, is to develop meaningful, intelligent human-like communication with machines.


Algorithms now navigate a vast amount of increasingly unstructured content (video, audio, images, sensors and devices) available to answer specifically or act upon a certain query. Data, enriched with semantic metadata, structure, and meaningful, machine-interprePage relationships, allows computer systems to find and manipulate information on our behalf with much greater precision.
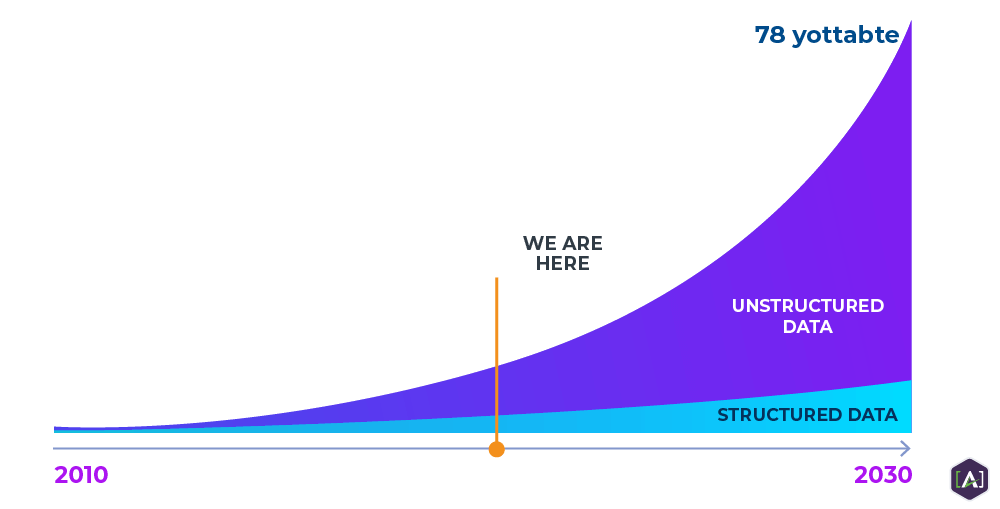
This results in better user experiences of content discovery and search, and broader opportunities for the seamless sharing, recombination, analysis, and reuse of data, with less human manual interaction in the loop. The Semantic Web makes it easier for humans to encounter frictionless content experiences, while a machine does the finding, sifting, sorting, combining, organizing, and presenting of real answers.
Standards set by the W3C for semantic metadata unlock a crucial evolution of the Semantic Web towards intelligence that allows the content we post online to be presented in a way that can be understood, connected, and remixed by computer systems.
The Semantic Web evolved over time.
 The first version of the Semantic Web - Web 1.0 - was the start of the digital era in the 1990s. The Web consisted mainly of static, read-only HTML documents which users ‘consumed’. Interaction did not take place.
The first version of the Semantic Web - Web 1.0 - was the start of the digital era in the 1990s. The Web consisted mainly of static, read-only HTML documents which users ‘consumed’. Interaction did not take place.
 The second incarnation of the Semantic Web - Web 2.0 or the ‘Social Web’ - started around 2004 with the take-off of social media and user interaction. The web became read/write and users became contributors. This became possible thanks to development of HTML5, CSS and JavaScript.
The second incarnation of the Semantic Web - Web 2.0 or the ‘Social Web’ - started around 2004 with the take-off of social media and user interaction. The web became read/write and users became contributors. This became possible thanks to development of HTML5, CSS and JavaScript.
 The third incarnation of the Semantic Web - Web 3.0 - has yet to be realized but is considered by many as the next evolutionary step of the Semantic Web. Some aspects have come close to being realized. In this version, the user also owns the data and data becomes decentralized.
The third incarnation of the Semantic Web - Web 3.0 - has yet to be realized but is considered by many as the next evolutionary step of the Semantic Web. Some aspects have come close to being realized. In this version, the user also owns the data and data becomes decentralized.
How does the Semantic Web work?
Berners-Lee provided a lingua franca for representing and linking data into a Semantic Web. The technological framework to bring the Semantic Web vision to life is built on standards, developed, agreed upon, and published by the W3C. These standards aim to provide a uniform and interoperable way for representing and managing data and content so that it can be easily shared and reused across applications, enterprises and individuals.
The original vision of the Semantic Web and its implementation gave rise to two data types:
Linked Open Data (LOD) and Semantic Metadata.
Linked Open Data
The term Linked Open Data (LOD) combines 2 concepts: Open Data and Linked Data.
Open Data (OD) is data that can be freely used, modified, and shared by anyone for any purpose. Data in this context is any structured web-based information.
The term Linked Data (LD) refers to a set of best practices for publishing and connecting structured data on the Web. Key technologies that support Linked Data are URIs (a generic means to identify entities or concepts on the Web), HTTP (a simple, yet universal protocol for retrieving resources, or descriptions of resources), and RDF(a generic graph-based data model with which data describing entities and concepts on the Web are structured and linked).
These key technologies provide a set of design principles for sharing machine-readable interlinked data on the Web. The Semantic Web is all about making links between resources understandable not only to humans but also to machines.
Linked Open Data (LOD) is Linked Data that is open. Tim Berners-Lee gives the clearest definition of Linked Open Data in distinction with Linked Data: "Linked Open Data is Linked Data which is released under an open license, which does not impede its reuse for free."
Tim Berners-Lee established the four design principles of Linked Data back in 2006:
1. Use URIs as names for Linked Data.
The Uniform Resource Identifier (URI) is a single global identification system used to identify real-world objects and abstract concepts as well as to identify the digital location where the object can be found. We refer to the Wikipedia article on URI for an excellent and detailed explanation.
2. Use HTTP in URIs to look up Linked Data
Several URI schemes exist to identify the location or delivery methodology: http, https, ftp, mailto, file, data and irc.
The http and https are protocols that simplify the identification of the location and retrieval of data stored on the World Wide Web.
3. Use standards (RDF, SPARQL)
To use URIs efficiently and support the Semantic Web concept, we use standards such as RDF or SPARQL. Those standards are already in place and are developed by the W3C. See more on standards below, in 3.3. Semantic Web Standards.
4. Include links to other URIs to improve discovery
URIs make interconnected data which facilitates the discovery of more information. By interlinking new information with existing data points, we create a richly interconnected ecosystem of machine-processable information and context.
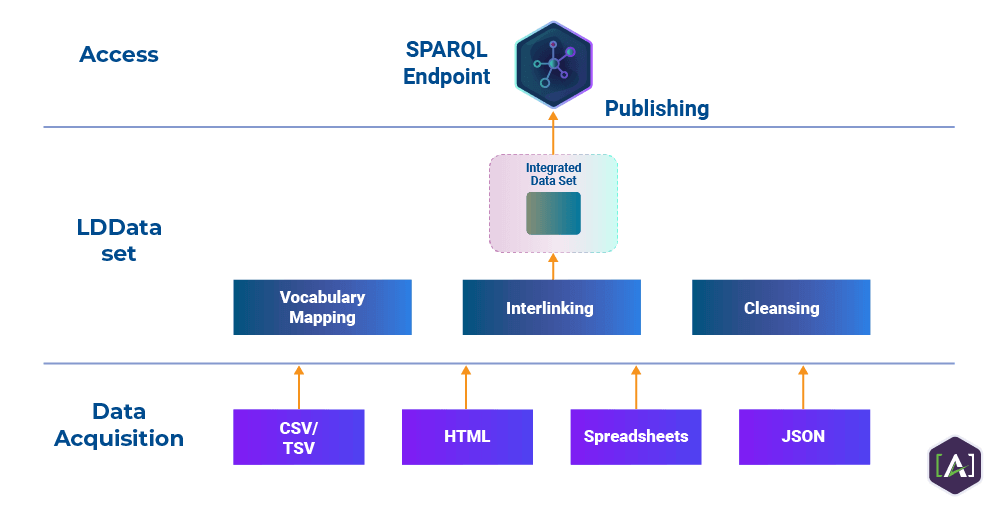
Using these design principles of the Semantic Web, Linked Open Data establishes a Knowledge Graph of all the data and content on the World Wide Web.
An example of the implementation of Linked Open Data (LOD) is the Europeana Foundation. All their data sets are public and can be explored and queried through the SPARQL API (see 3.3. Semantic Web Standards).
Semantic Metadata: Tagging the Internet and beyond
Metadata is additional data that describes data. An example of unstructured data is a picture. Metadata could be any additional data about the picture: where it was taken, the date it was taken, who took the picture, which device was used, etc.
Semantic metadata is additional data that provide meaning about the data itself.
In the context of the web, semantic metadata, also known as semantic tags, provide additional data about the web page content to describe its meaning to machines. Semantic tags are often designed and presented specifically for machines.

Semantic metadata can also help resolve ambiguity in certain search queries. This creates semantic interpretations of the same query and the search results can be ranked specifically for a particular semantic interpretation of a query.
Google has patented “techniques for evaluating different interpretations of a particular search query.”
The query “how long is harry potter” creates a lot of ambiguity as numerous interpretations can be given:
- Any of the seven books in the Harry Potter franchise
- Any of the film adaptations of the books
- A ride
- Theme park
- Audiobook
- Cartoon
- Etc.
Read the “How Google May Interpret An Ambiguous Query Using a Semantic Interpretation” article for a detailed description of how Semantic Interpretations work.
Semantic metadata is not only useful for web pages as a whole but also provides meaning to unstructured data such as pictures. Computers can determine a file is an image based on its file format (jpg, png, etc) but a computer can not ‘see’ the image and understand what it shows. To do that, computers require semantic metadata, which is a structured form of data about unstructured data.
The most elaborate and popular structured metadata schema is Schema.org which was established by Google, Yahoo, Microsoft and Yandex. Imagine the importance of semantic metadata for search engines and the Semantic Web as a whole for four major competitors to join forces.
For detailed information about Schema read our articles “What is Schema.org?” and “Schema Markup for SEO”.
Semantic Web Standards
The technology stack that supports the Semantic Web is designed to enable computers, software systems, and people to work together in a network. It consists of a wide array of technologies, the most important of which are: RDF, SPARQL, OWL.
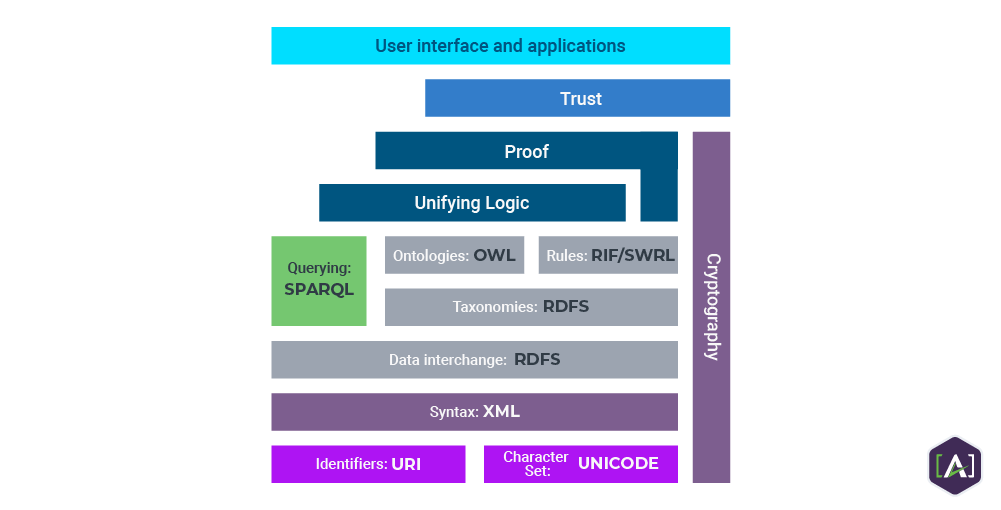
RDF stands for Resource Description Framework and is a method for publishing and linking data. It is built around the following Web standards: XML and URL (URI) and uses the model of the “triple”—three elements (namely a subject, a predicate and an object) bound together, with the relationships between them formally described. When there are enough triples, they form a rich graph of knowledge.
SPARQL stands for Protocol and RDF Query Language and is the way data stored in stands for the W3C Web Ontology Language. OWL is a logic-based language, designed to be interpreted by machines so that they can automatically process and reason through the information it describes.
OWL stands for the W3C Web Ontology Language. OWL is a logic-based language, designed to be interpreted by machines so that they can automatically process and reason through the information it describes.
XML provides an elementary syntax for the structure of content within documents but does not associate any semantics with the meaning of the content it contains. XML is not a necessary component of Semantic Web technologies, as alternative syntaxes exist, such as Turtle. Turtle is a standard on a practical level, but has not undergone a formal standardization process.
RIF is the W3C Rule Interchange Format. It’s an XML language for expressing Web rules that computers can execute. RIF provides multiple versions, called dialects. It includes a RIF Basic Logic Dialect (RIF-BLD) and RIF Production Rules Dialect (RIF PRD).
The realization of the Semantic Web

The vision of humans and machines being able to communicate in meaningful ways seemed like a utopian vision back in the 1990s. Thanks to advancements in Artificial Intelligence, ML and NLP this part of the Semantic Web vision has come very close to reality.
Amazon is a company that applies semantic metadata combined with AI and Big Data to give users meaningful experiences, ‘guessing’ what kind of product they are looking for and then fine-tuning product recommendations personalized to their needs. Amazon has been able to offer this level of meaningful experiences and communication between humans and computers across devices, through text and voice.
Google is a company that not only has adopted some of the vision of the Semantic Web, but it has also been actively promoting and implementing the original ‘utopian’ Semantic Web vision of Tim Berners-Lee.
As a search engine, Google's business model is based on being able to understand the meaning of searches (also known as search intent) and the content of web pages, and being able to decode optimal matches and deliver these "search-content" matches in the most user-friendly way possible.
Over the past two decades Google has:
- Co-developed Schema.org - a form of Semantic metadata - and has been actively pushing the adoption of Schema markup.
- Develop ‘rich snippets’ - alternative forms of displaying information about queries in more meaningful and user-friendly ways.
- Apply the concept of Linked Open Data (LOD) through the creation of a Knowledge Graph of Things.
- Google is an R&D pioneer at the cutting edge of Artificial Intelligence (AI), Machine Learning (ML) and Natural Language Processing (NLP), as well as knowledge graphs. Find more information on Google’s research here.
- Google has been applying its research in AI, ML and NLP technology for its ranking algorithm, voice assistant and client products. Some of the most remarkable applications are:
- The Hummingbird update (2013) introduced the groundwork for voice-search, which has become more and more important to more devices (Google Home, Alexa). Hummingbird also improved semantic and contextual understanding of queries by paying more attention to each word in a query, ensuring that the whole search phrase is taken into account, rather than just particular words.
- With the RankBrain algorithm, Google started employing machine learning to handle queries. Its release marks a big step for Google to better decipher the meaning behind searches, and serve the best-matching results. In March 2016, Google revealed that RankBrain was one of its three most important ranking signals. Unlike other ranking factors, you can’t really optimize for RankBrain in the traditional sense, other than by writing quality content.
- The release of BERT in 2019 marked another step towards improved application of Semantics and understanding Context. BERT is a machine learning algorithm, a neural network-based technique for natural language processing (NLP) that can figure out the full context of a word by looking at the words that come before and after it. It uncovers relations between all the words in a sentence and derives context from those relations. This has led to a big improvement in interpreting a search query and the intent behind it.
- MUM brought what Google had been announcing for some time: A shift towards a purely Semantic Search Engine emphasizing even further the importance of Schema Markup, quality content and the use of AI. MUM is too complex to briefly explain here. Please read the terrific article linked previously.
For more information on Schema Markup and Rich Snippets, see the Additional Resources at the bottom.
Today Google embodies part of the Semantic Web vision, and in fact, Google has been developing advanced technologies to create its Knowledge Graph of all available Open Data (and content) by mapping all relationships between entities. In addition, it uses advancements from the technology it has pioneered to refine the understanding of the meaning of queries and deliver meaningful results through even better communication channels. At the same time, companies such as Google, Amazon, and Facebook also embody much of the criticism about the current state of affairs, called Web 2.0 (see below in section 6.3. Challenges ahead for the Semantic Web).
What are the benefits of the Semantic Web?
Semantic Web standards support Big Data
One major and somewhat less visible advantage of the Semantic Web lies in its standards. Those standards (RDF, OWL, SPARQL) provide a common framework that allows computer systems to create meaningful relationships between disparate data resources and make the meaning of those resources explicit.
In today’s business environment, unstructured data has become one of the most valuable resources and its growth rate is staggering. Nowadays, 80% of all data in organizations is unstructured data, and organizations struggle to extract value from it. Enterprises are overwhelmed by a flood of available, but not very usable, information. The real problem is context. It’s difficult to extract value from information unless it’s well described.
Thanks to the Semantic Web standards, it’s extremely easy to connect and remix different data sets through the RDF data structure, because of its simplicity and optional nature. Big data projects will see this as a useful advantage, as different types of information within an enterprise can sometimes be problematic to analyze and organize.
Another related benefit is the enormous amount of data, information and knowledge that is translated to be machine-ready, including virtual assistants, agents and AI bots. Not only is the availability of data a big advantage, but also the relationships that are created between data sets in knowledge graphs.
Enterprise Level Operational Benefits
Cost reduction and much faster turnaround on Data Projects.
AI-assisted data modeling tools are available to reduce the cost and time of creating data models that incorporate Semantic Web standards and public domain vocabularies. These tools that combine AI, data modeling, and Semantic Web standards enable companies to model faster, with fewer errors, and can be rolled out across the enterprise quickly.
Data classification processes enable metadata creation and data harmonization for a better user experience. RDF output and access to a SPARQL endpoint make the data flexible, and dynamic and provide a broad canvas for exploration to solve business problems in ways not possible with traditional technology.
Since semantic web standards - in combination with AI and NLP - provide very impactful operational benefits for Big Data processing and analysis - especially with unstructured data - it is likely that semantic web standards will be increasingly incorporated into data modeling projects.
Search & SEO
Another advantage of the semantic web is the improvement of users' search results. Search engines, and Google, in particular, have become very good at understanding what is being searched for and delivering the exact content that is being sought.
Semantic metadata, such as schema markup and Google's knowledge graph, help understand meaning, context, and search intent and provide the best matches to user queries. One of the main implications this has had on SEO is that content value has become a key ranking factor. Content must be of high quality and it must provide value to users. Competition has caused publishers to put more and more high-value content on the web.
Improved search and the use of Semantic Metadata is not limited to search engines; it is also being applied to company help centers and intranets for better internal content retrieval.
Another important SEO benefit is the availability of specific backlinks coming from websites that demonstrate trustworthiness, specifically if links are coming from sources that are included in the DBpedia open knowledge graph. Data has demonstrated that web pages with backlinks from those sources rank higher in SERPs.
Better user experience
The end users will be the ones benefiting the most from the Semantic Web and its underlying technologies. It creates vastly better user experiences when we use search engines to retrieve information and in the way we interact with machines.
The Semantic Web not only improves traditional search, but also facilitates more seamless, intelligent, and integrated user experience journeys. For example, with semantically connected and described data, a digital assistant could send users local live music recommendations in their area. This could be possible by gathering and connecting disparate data published on the web like information about nearby venues posted online and linking it to the data about the type of music a user has chosen to share on their online playlists.
One additional dimension of the Semantic Webs’ vision is the ability to communicate with machines by voice the same way one does with a person. It is now common to communicate with virtual assistants like Apple’s Siri, Google Assistant or Amazon’s Alexa, but it is not yet 100% perfected to create complex conversations, nor has it been fully integrated into the web and other devices. But that day is coming closer at breakneck speeds as yet another recent AI/NLP related publication demonstrated.
The future of the Semantic Web - Web 3.0
A Purely Semantic Web
Content discovery and presentation on Google and Bing are just the tip of the iceberg of what the Semantic Web and semantic metadata have to offer. In terms of intelligent content applications, the emerging Semantic Web of content and data is a great opportunity to seize.
We are currently progressing towards a purely Semantic Web with the aid of AI and semantic metadata such as schema markup. While Google has actively driven this trend towards a Semantic Web, many companies still have to implement schema markup on their websites to provide better semantic data to search engines, as well as incorporate machine-readable markup.
While many content publishers are still struggling to implement semantic metadata, tech companies are already developing next-generation devices and computer systems to take advantage of the technology that aided the creation of a Semantic Web, such as AI, NLP, blockchain technology, and semantic metadata, to create incredibly complex, safe and meaningful user-experiences.
The spread of the Semantic Web and the technologies it brings to the Page puts the analytical powers of machines to work in the domains of content production, management, learning, support, media, ecommerce, scientific research, knowledge management, and publishing in general. Anywhere we express knowledge will become semantic. This transformation is making the web much more dynamic, allowing content and data to travel freely and seamlessly.
The Semantic Web beyond the Web
As the use of semantic metadata becomes more widespread beyond Google and search engines, and in combination with the power of AI and NLP, its applications will expand to the IoT (Internet of Things), to smarter devices: from existing voice-in-a-box assistants like Alexa to smart wearables, to multifunctional autonomous robots that can be used in numerous scenarios. Examples of current use are robots that welcome people in restaurants, to robots that become home assistants as in Sci-fi movies
As such, the future of the Semantic Web probably lies beyond the traditional concept of the Web towards a broader digitalized world in which our interaction with computer systems will increasingly move beyond computers and cellphones into IoT (Internet of Things) and robotics. Soon we'll be talking to mirrors, cars, a variety of robots, all systems in which the foundations of the Semantic Web will be incorporated to achieve intelligent, meaningful, human-like interactions.
Challenges ahead for the Semantic Web
The original vision of The Semantic Web as described by its inventor Tim Berners-Lee consisted of two main parts:
- The ability to have meaningful, human-like communication with machines
- Create an open and free World Wide Web based on Linked Open Data
While the first part is not yet 100% achieved, thanks to numerous technological developments, we have come very far and are coming closer to that vision of meaningful human-like communication with machines.
The other major part of the Semantic Web vision is the idea of data being freely and openly shared, distributed worldwide, accessible, and building interrelated knowledge bases. However, the current incarnation of the Semantic Web (Web 2.0) falls short of this vision. The current use of linked data occurs in highly centralized data silos, and the sharing and re-use of knowledge are cumbersome and not very easy.
The technology exists but the concept of Open Data clashes with corporate interests. One criticism of Web 2.0 is that we, the end users, have become the product. User data is very valuable and the basis of business models of most large technology companies.
The core of the debate between Web 2.0 and Web 3.0 is a philosophical debate between "people power" and "corporate interests", with many open questions that still need to be answered.
For more information on proposals from Web 3.0 advocates visit https://contractfortheweb.org/
In the not-too-distant future, we will be able to have conversations with our mirror in the morning about our state of health and how to adjust our diet and exercise based on health data collected over time and let an intelligent home assistant schedule a needed doctor's appointment. Although this is done over secure networks with proprietary information, it seems to come as close as possible to part of Tim Berners-Lee's vision of the semantic web.
And even in that scenario, the data will not be open, it will most likely be a service provided by a company for which the user will have to pay in one way or another, and the data will be protected by numerous laws governing privacy and confidentiality.
So, does this mean there will be a Semantic Web or Web 3.0?
The answer is NO.
The Internet will evolve, but not necessarily according to the dominant vision of Web 3.0. It will probably not progress in a decentralized way from power to people, but rather somewhere in between. Semantic metadata and AI will continue to develop to provide ever-better communication between humans and machines. But it is unlikely that, from an operational and financial point of view, a fully decentralized and open version of data will become a reality.
How to get started with the Semantic Web?
Although the applications of the Semantic Web are endless, we cannot take advantage of these possibilities until we have a truly intelligent web of global knowledge. To achieve this, we must make our content ‘semantic’, or annotated with meaningful metadata and relationships to transform dull and dormant fixed text into live and intelligently linked concepts.
We need to graph our own content sets and connect them to globally related content sets. Start locally. Start at home, in our own enterprises. Then reach out to connect to the content within related content ecosystems of customers, partners, vendors, and even competitors.
Content Engineering brings the Semantic Web to Life
In order to engineer content in such a way, we need to understand the significance of semantic data connections and begin to incrementally embed semantic metadata and relationships into every piece of content we design.
Using Semantic Web Technologies, publishers can:
- Build smart digital content infrastructures
- Connect content silos across a huge organization
- Leverage metadata to provide richer experiences
- Curate and reuse content more efficiently
- Connect internal and external content sets
- Build towards real augmented and artificial intelligence
- Power-up authoring experiences and workflow processes
Those of us in the content industry, or anyone involved in content publishing inside an enterprise, can seamlessly build this semantic intelligence into our content sets, but not overnight. A nimble structure for knowledge takes discipline and the application of patterns over time.
It is through the practice of Content Engineering, in connection with smart content strategy, that content ecosystems are designed for rich semantic connections and personalized omni-channel user experiences, in text and voice.
Content engineers are creating a more powerful and agile web of content and data by first parsing and structuring the discrete elements of content that constitute websites, such as people, events, ideas, concepts, products. These elements are then assigned Semantic Tags that describe their meaning in a standardized language. When machine-readable descriptions are present, they can be linked to build a more robust web of data where computers can find, read, and even reason about a unit of content.
We can see the application of semantic data in various places throughout the web, such as certain search experiences. Because of this rich new layer of information, search engines and other bots are able to provide the most relevant content directly to the user, reduced to the most important snippets that can save humans time and effort.
A Core Content Model and Core Semantic Model play a crucial role in implementing Content Engineering and developing modular content for personalized contextual omni-channel content delivery.
Use the right tools to implement the Semantic Web
Schema Markup
Schema markup can be implemented on websites using WordPress or other traditional content management systems (CMS) However, most of these tools have limited flexibility, control, and scope of schema types that can be implemented. They are adequate for small websites with static content but for large websites and dynamic content publishers, these tools fall short.
Large data sets and content rich enterprises need more complex tools like Headless CMS, DAM and data management solutions.
For publishing content enriched with semantic metadata, the ideal solution is a Headless CMS. These tools allow you to map your web content with semantic metadata (schema markup).
Semantic Tools
These tools are aimed at integrating semantic web standards (RDF, OWL, SPARQL) in data sets to enrich data, data exchange, and data analysis.
These tools often have data modeling functions to increase project efficiency.
PoolParty Semantic Suite is a semantic middleware platform on the global market. As a middleware, PoolParty serves as the powerful “glue” between customer databases and applications so that customer knowledge models can continuously evolve in a sPage, interconnected environment.
Semaphore from Smartlogic is an AI driven Semantic platform that reveals qualified contextual data using a centralized integrated platform that identifies enterprise information with capabilities to create and manage semantic metadata, active metadata, and information extraction.
Graph Database & Knowledge Graphs
Knowledge Graphs are becoming widespread as an analytics tool for Big Data, to analyze relationships and patterns that are hard to discover for humans in an overwhelming ocean of data.
Graph databases with Semantic modeling capabilities are very useful for storing relational data or discovering relations between diverse data sets.
Several graph database providers exist:
- Ontotext introduced the concept of semantic annotation: the process of interlinking text with big knowledge graphs. Through semantic annotation, the AI can explore, create and discover relationships in vast amounts of text based data and develop an enterprise knowledge graph for data analytics.
- Smartlogic has developed an AI driven platform to identify and extract the valuable information hidden in unstructured text and siloed structured information into a single harmonized datastore. Organizations leverage this semantically harmonized and enriched data, which is of high quality and contains the full set of enterprise information, to integrate data, discover knowledge, and perform in-depth analysis across the enterprise.
Headless CCMS
A Headless CCMS or Component Content Management System - read our article "What is a Content Management System? (CMS)" to learn more about the different types of CMS.
Get help from [A]’s Content Engineering Experts
Simple [A]’s Content Engineers are experts with years of experience in implementing Content Management Systems in large organizations. [A]’s expertise lies mainly but not exclusively in implementing headless component content management systems and Jamstack architectures.
Simple [A] distinguishes itself by its holistic approach to Headless CMS solutions, applying our content modeling and Content Engineering expertise, to assure companies have highly streamlined efficient content supply chains from authoring to multi-channel publishing, while at the same time fostering personalized next-level Customer Experiences using a Content-as-a-Service (CaaS) model.
Simple [A] is a Kentico, Sitecore and Contentful partner, but we can assist with the implementation of any headless CMS on the market or even assist in developing a custom CMS.
Simple [A] assists organizations along this entire process ensuring the journey is frustration-free and frictionless, and has a successful outcome for your organization.
[A] is proud to be a:
- PoolParty Semantic Suite Partner
- Semaphore Semantic Platform Partner
- Kentico Gold partner since 2008
- Sitecore Certified Solution partner
- Contentful Partner
Contact ustoday to discuss how we can assist your organization with implementing Content Engineering practices, data modeling, Semantic Metadata, Schema Markup and taking advantage of the Semantic Web.
Additional Resources
We recommend the following articles for more information on related topics:
The Core Content Model The Core Semantic Model Schema MarkupImplementation Guide






